Консоль поиска Google только начала поддерживать регулярные выражения (RegEx) в фильтрах. Посмотрим, как можно использовать RegEx для анализа данных GSC.
Эта статья предназначена для изучения регулярных выражений, которые вы можете использовать в Google Search Console и которые соответствуют синтаксису Re2.
Регулярные выражения — это обозначения для описания наборов символьных строк. Когда конкретная строка входит в набор, описываемый регулярным выражением, мы говорим, что регулярное выражение соответствует строке.
Два регулярных выражения можно чередовать или объединять для образования нового регулярного выражения: если e1 соответствует s, а e2 соответствует t, то e1 | e2 соответствует s или t, а e1e2 соответствует st.
Метасимволы *, + и? являются операторами повторения: e1 * соответствует последовательности из нуля или более (возможно, разных) строк, каждая из которых соответствует e1; e1 + соответствует одному или нескольким; e1? соответствует нулю или единице.
Приоритет операторов, от самого слабого до самого сильного связывания, — это сначала чередование, затем конкатенация и, наконец, операторы повторения. Явные круглые скобки могут использоваться для обозначения разных значений, как и в арифметических выражениях. Некоторые примеры: ab | cd эквивалентно (ab) | (cd); ab * эквивалентно a (b *).
Синтаксис, описанный до сих пор, является большей частью традиционного синтаксиса регулярных выражений egrep Unix. Этого подмножества достаточно для описания всех обычных языков: грубо говоря, обычный язык — это набор строк, которые могут быть сопоставлены за один проход по тексту, используя только фиксированный объем памяти. Новые средства регулярных выражений (особенно Perl и те, которые его скопировали) добавили много новых операторов и управляющих последовательностей, которые делают регулярные выражения более краткими, а иногда и более загадочными, но обычно не более мощными.
Начало работы с RegEx в Google Search Console
Консоль поиска Google использует синтаксис Re2 и не поддерживает все синтаксисы регулярных выражений, которые вы, возможно, знаете.
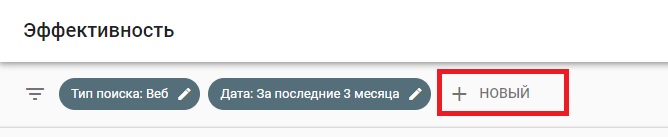
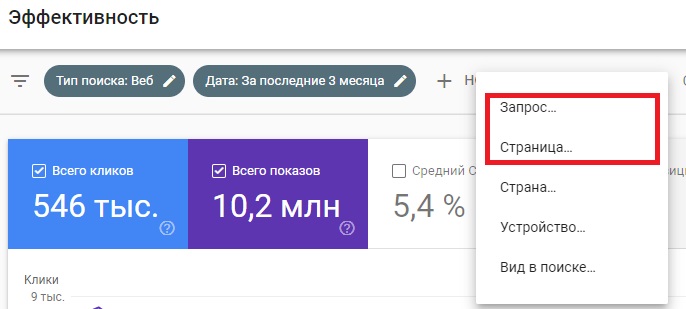
Фильтрация по регулярному выражению доступна для отчетов по страницам и запросам.
Чтобы отфильтровать отчет о производительности с помощью регулярных выражений, нажмите «Создать» и выберите «Запрос» или «Страница».
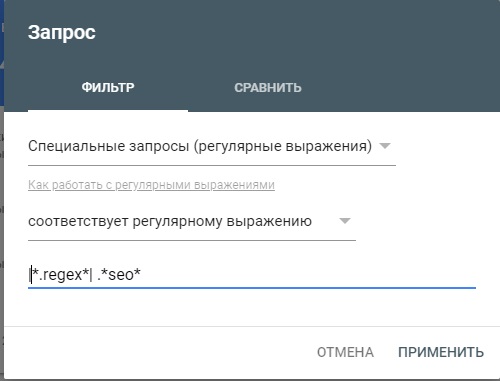
Добавьте свое регулярное выражение и отфильтруйте отчет.
Ограничения на количество символов
В Google Search Console ограничение на количество символов составляет 4096 символов. Обычно этого достаточно.
С помощью регулярных выражений вы можете сделать свой узор более сжатым, чтобы сохранить символы.
example.com/aa|example.com/bbравно:
example.com/(aa|bb)Соответствие всем страницам / запросам, содержащим слово
Чтобы отфильтровать страницы или запросы, содержащие слово, просто оберните это слово в .*.
Это будет соответствовать чему-либо до и после вашей строки. Здесь я сопоставляю все, что содержит это слово seo.
.*seo.*.*соответствует чему угодно.
Соответствие определенным страницам
Чтобы соответствовать определенным страницам, напишите свое свойство вместе с группой захвата ()для URI.
^https://www.example.com/(page-one|google-search-console-api|reddit-api)/$()группа захвата, чтобы сгруппировать элементы вместе|означаетOR^начинается с$заканчивается c
Отрицательная фильтрация с помощью RegEx
Первой реакцией SEO-сообщества на новую фильтрацию регулярных выражений в Google Search Console было то, что в Re2 не поддерживался отрицательный поиск .
Google быстро отреагировал и придумал отрицательную фильтрацию с помощью регулярного выражения.
Теперь вы можете использовать фильтр «Не соответствует регулярному выражению» с настраиваемым фильтром.
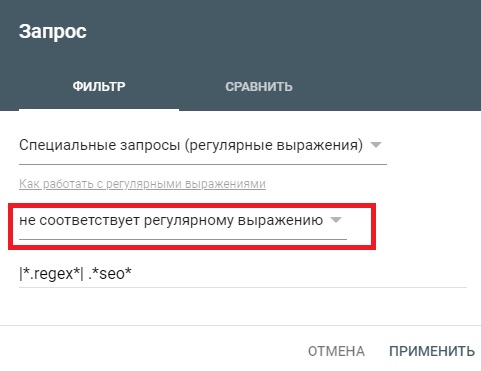
Фильтр длины запроса/URL с плмощью регулярного выражения
Короткие шаблоны длиной менее 10 символов.
^[\w\W\s\S]{1,10}$Результаты
seo
python
regex
regex for SEOРезультаты отфильтрованы
long-tail queries with more than 10 characters[]соответствует диапазону символов^начинается с$заканчивается\wсоответствует букве ASCII, цифре или знаку подчеркивания. Это то же самое, что и[A-Za-z0-9_]\g;\sсоответствует пробелу;\Wсоответствует всему, что не является буквой, цифрой или символом подчеркивания ASCII;\Sсоответствует всему, что не является пробелом.{1,10}повторения узоров от 1 до 10 раз.
Находите длинные запросы с помощью регулярных выражений
Приведенный ниже RegEx будет соответствовать любому запросу, длина которого превышает X символов (в данном случае 70).
^[\w\W\s\S]{70,}$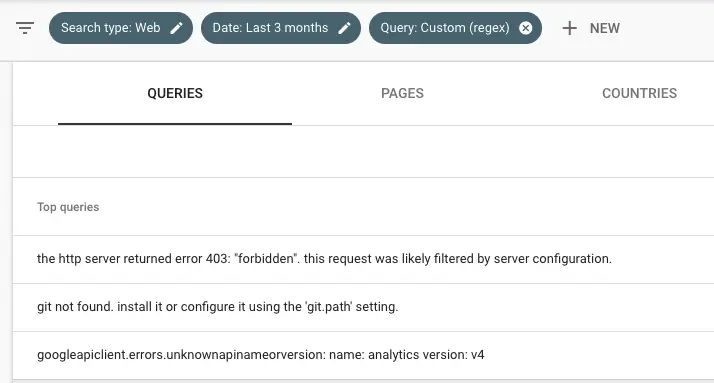
Другое решение — подсчитать количество пробелов для определения количества слов.
(\w+\s){7,}\w+^начинается с$заканчивается[\w\W\s\S]любой персонаж{70,}70 раз и более(\w+\s)Любое количество слов от 1 до неограниченного числа раз с последующим пробелом{7,}7 раз и более\w+оканчивающийся словом
Найти очень длинные URL
Используйте это регулярное выражение для фильтрации URL-адресов страниц, длина которых превышает 100 символов.
^[\w\W\s\S]{100,}$URL-адрес, содержащий специальные символы
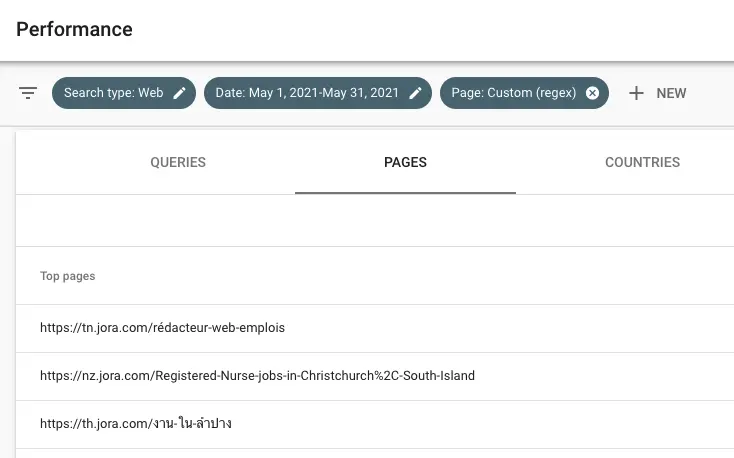
[^]исключить диапазон символов\/\.\-\:Исключите символы, не являющиеся словами, которые являются общими в URL-адресах (например,://в протоколе и пунктир-между словами)0-9A-Za-z_символы слова, которые нужно исключить из регулярного выражения.
Показать конкретный URL
Иногда вам просто нужно сопоставить определенный путь.
/<category>/<sub-category>/<feature>
.*/jobs/.*/melbourne$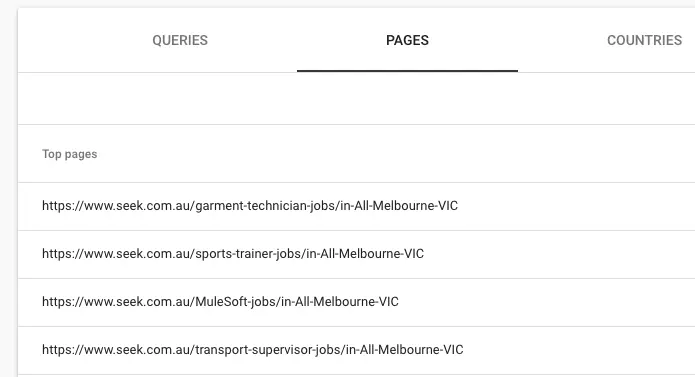
Это может соответствовать
/jobs/sales/melbourne/jobs/marketing/melbourne- …
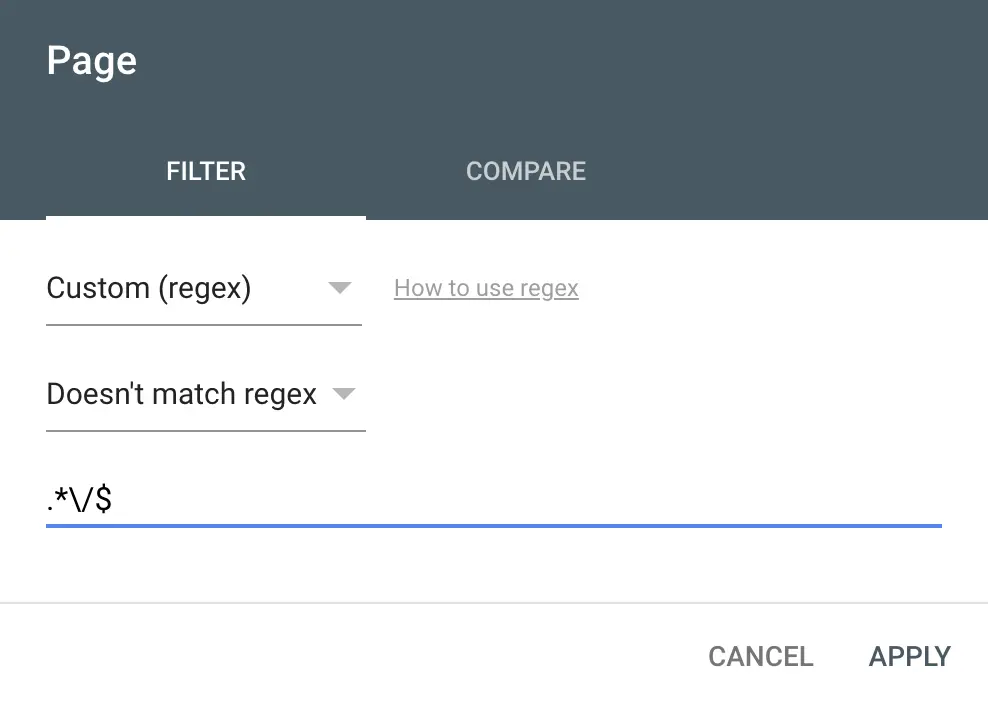
Заканчивается косой чертой в конце
Показать страницы, которые содержат (или не содержат) завершающую косую черту в конце.
.*\/$
Показать варианты HTTP / HTTPS / поддоменов
Хотя рекомендуется проверять ваш сайт в консоли поиска Google как на уровне домена, так и на уровне отдельного префикса URL, вам может потребоваться быстрый способ проверить свойство вашего домена на наличие проиндексированных поддоменов или вариантов HTTP / HTTP.
https?\:\/\/.*example\.com\/?$Это быстрый способ определить поддомены, которые, возможно, не проиндексированы.
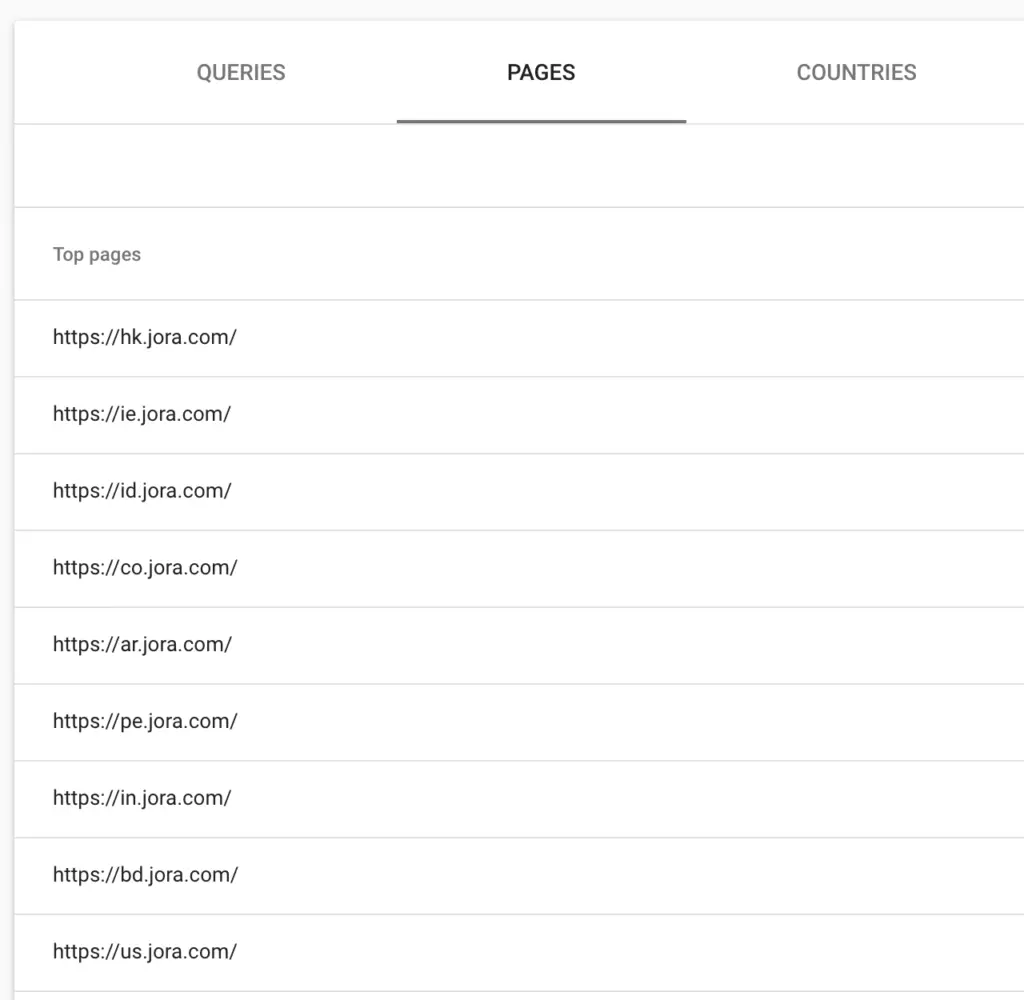
https?соответствует http или https\/?$заканчивается косой чертой в конце или нет.
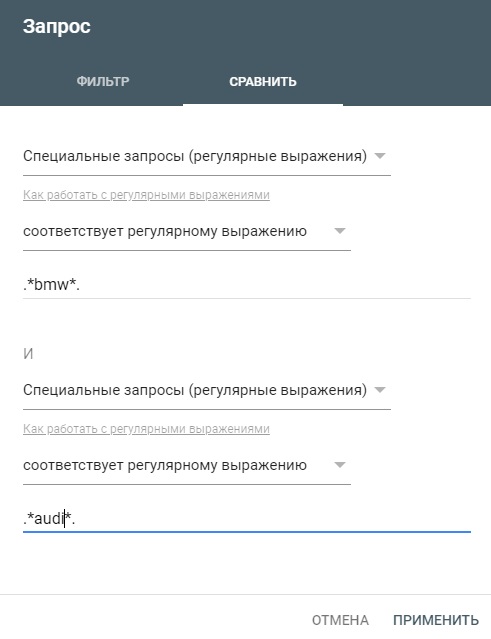
Сравнение регулярных выражений
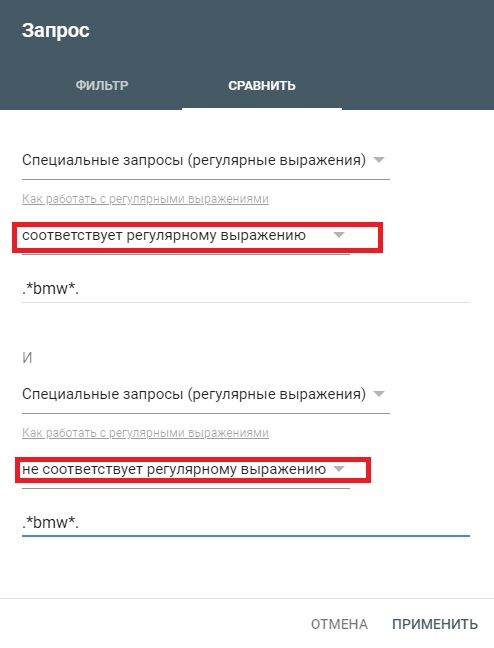
Возможно, вы захотите сравнить страницы или запросы на основе регулярных выражений.
Вы также можете использовать фильтр сравнения с регулярными выражениями.
Понять намерение пользователя (интент)
Показать запросы, определяющие различные намерения пользователя.
Информационный запрос
who|what|where|when|why|how|was|did|do|is|are|aren’t|won’t|does|if|can|could|should|would|won’t|were|weren’t|shouldn’t|couldn’t|cannot|can’t|didn’t|did not|does|doesn’t|wouldn’tНавигационный запрос
.*brand.*Коммерческий запрос
.*(best|top|vs|review*).*Транзакционный запрос
.*(buy|cheap|price|purchase|order).*Запросы без учета регистра
Хотите сделать запросы нечувствительными к регистру? Добавьте (? I) в начало выражения.
(?i)^(who|what|where|when|why|how)[" "]
Соответствие брендовым условиям
Часто в поисковых запросах есть орфографические ошибки. Вы можете правильно оценивать поисковые запросы по брендам с помощью регулярных выражений.
Приведем пример с возможными орфографическими ошибками в Linkedin.
- lnkedin, linkeidn, linkden, linedin, linkein, Likein, linkin, linkedin, linkd, amazon connectedn
Вы можете использовать строку с длинным регулярным выражением:
.*lnked*in.*|linke*idn.*|linkd*en.*|lined*in.*|linke*in.*|liked*in.*|link*in.*|linked*in.*|.*linkedn.*|.*linkd.*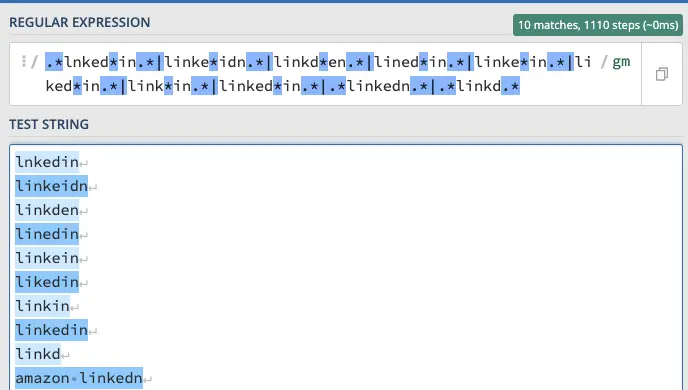
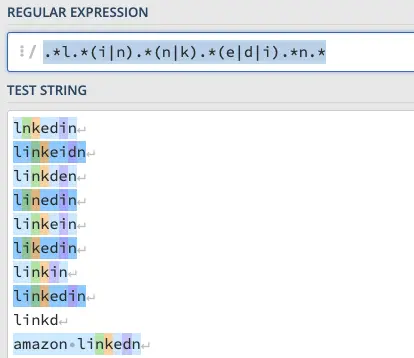
Или точнее.
.*l(i|n){1,2}(k|e).*n.*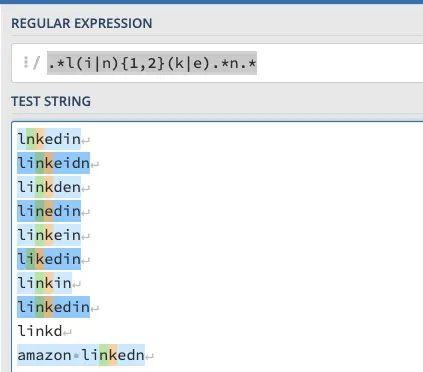
Можно использовать несколько шаблонов.
Сравните брендовый и небрендовый трафик
Проверьте наличие потенциальных инъекций контента
Внедрение контента — это способ внедрения на ваш сайт страниц, содержащих определенные ключевые слова. Вот как вы можете проверить наличие распространенных инъекций на вашем сайте.
Используйте это регулярное выражение в регулярном выражении страниц, чтобы проверить, совпадает ли оно.
.*viagra.*|.*cialis.*|.*levitra.*|.*drugs.*|.*porn.*|.*www.*www.*Проверьте URL-адрес админки WordPress
Довольно просто проверить страницы админпанели WordPress, которые казались проиндексированными.
.*wp-.*Показать почтовые индексы в URL-адресах
Перечислить URL-адреса, заканчивающиеся почтовым индексом.
https://example.com/Sales-jobs-in-Wembley-HA0
https://example.com/Sales-jobs-in-Corstorphine-EH12
https://example.com/Marketing-jobs-in-Corstorphine-EH12
https://example.com/Retail-jobs-in-Bourton-BS22В Великобритании почтовые индексы состоят из одной или двух букв, за которыми следуют одна цифра, две цифры или одна цифра и одна буква.
.*-[A-Za-z]{1,2}(\d{1,2}|\d[A-Za-z])$[A-Za-z]{1,2}: Соответствует одной или двум буквам\d{1,2}: Соответствует одному или двум числам\d[A-Za-z]: Соответствует цифре и букве( pat1 | pat2 ): Группировка шаблонов ИЛИ
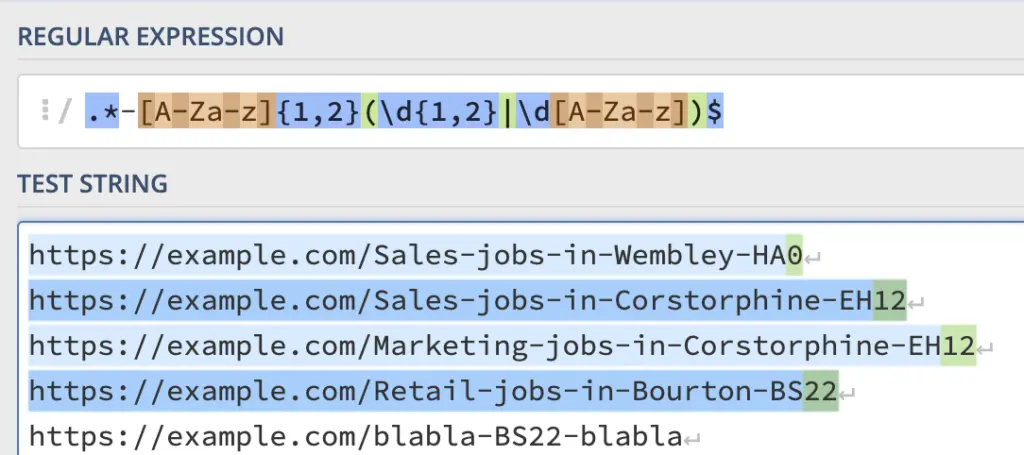
Должно работать, но не работает
Иностранные символы в URL-адресах
Согласно документации Re2, такие классы символов Юникода должны работать:
\p{Greek}
Это было бы полезно для определения шаблонов URL-адресов, в которых есть некоторые из иностранных символов, которые наиболее часто используются во взломах с внедрением контента.
.*\p{Hiragana}.*|.*\p{Cyrillic}.*|.*\p{Hangul}.*|.*\p{Han}.*|.*\p{Thai}.*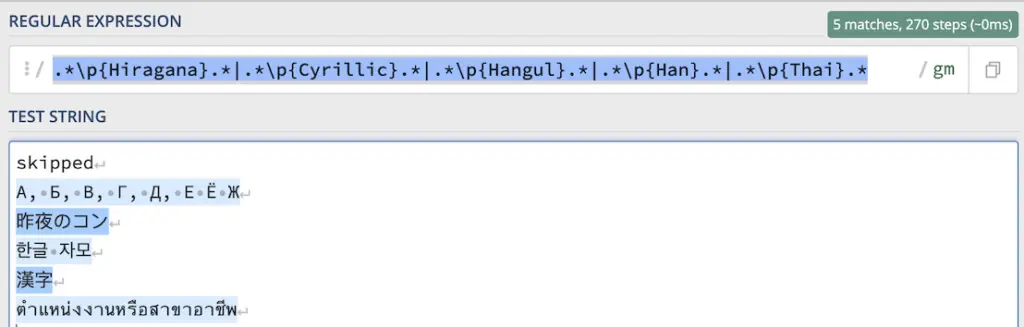
Он работает с регулярными выражениями запросов, но не работает с URL-адресами.
Дополнительные регулярные выражения
Некоторые дополнительные регулярные выражения для GSC
# Matches URL slug
^[foo]+(?:-[bar]+)*$
# All urls within /page
(http|https):\/\/www.example.com\/page\/.*
# All urls between a certain slug and ending
(http|https):\/\/www.example.com\/slug\/[^\/]+\/page
# Matches all queries containing a specific term (all work)
\b(\w*foo\w*)\b
\b(\w*foo\sbar\w*)\b
^hello\sworld$
# Matches all queries containing "blue shoe" or "blue shoes"
(\W|^)blue\s{0,3}shoe(s){0,1}(\W|$) //works
# Matches all queries that contain "Ciffone" or "Ciffone Digital"
^.*(ciffone|ciffone digital).*$
# Match Word or Phrase in a List
(?i)(\W|^)(foo|bar|foo\sbar)(\W|$)Оригинал статьи — https://www.jcchouinard.com/regex-in-google-search-console/